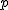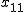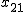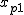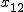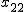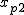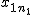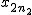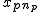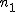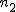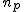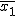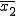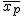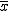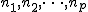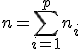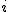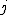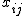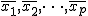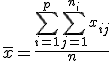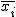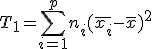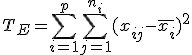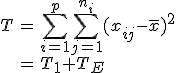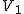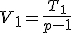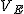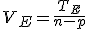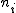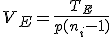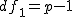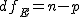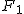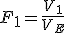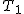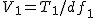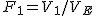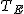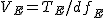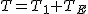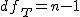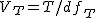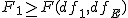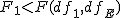一元配置分散分析
検定の対象因子と水準対応のない複数の組の標本について考える。 例えば、3つの血圧降下剤(A薬、B薬、C薬)の効果を調べるために、 15人の被験者を無作為に3つのグループに分けて、 それぞれのグループにA薬、B薬、C薬いずれかを投与して 収縮期血圧を測定したところ、 次の表のようになったとする。
一般には、一元配置分散分析のデータは、次のような表で書くことができる。
表のデータは、次のことを表している。
全変動と級間変動と誤差変動ここで、第
1元配置分散分析
帰無仮説と対立仮説対応のない3組以上の標本の平均値に差があるかどうかを調べる。
検定統計量の算出
「分散分析表」にまとめると、次のようになる。
仮説の判定(片側検定)検定統計量
|
メニュー授業内容ケータイで教員にメール今日の5件最新の10件2025-06-302025-06-232025-06-172025-06-16 total: 17373 today: 1 yesterday: 2 now: 2 |