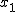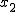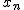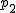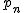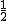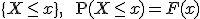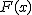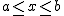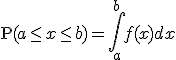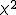確率分布と確率密度関数確率変数と確率分布確率変数 (random variable)
確率分布 (probability distribution)
確率分布の例
確率密度関数確率変数の種類
確率密度関数と累積分布関数
確率分布の分類確率変数が離散的か連続的かで、次のように確率分布を分類することがでます。 テキストで取り上げられている、おもな分布を挙げておきます。
|
メニュー授業内容ケータイで教員にメール今日の5件最新の10件2025-06-302025-06-232025-06-172025-06-16 total: 2040 today: 2 yesterday: 1 now: 4 |
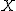
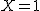
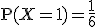
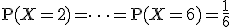
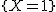
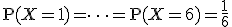
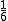
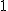
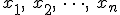
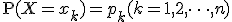
![\left\{ p_1 \geq 0, \hspace{5} p_2 \geq 0, \hspace{5} \cdots , \hspace{5} p_n \geq 0 \\[10] p_1 + p_2 + \cdots + p_n = 1 \right.](cache/29eec1e4f28a90adf74d0d7620cd588a.mimetex.gif)