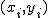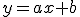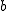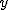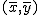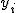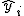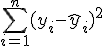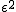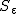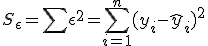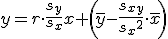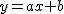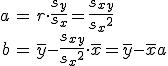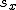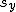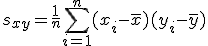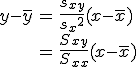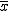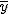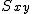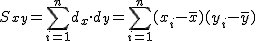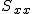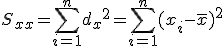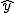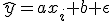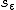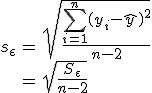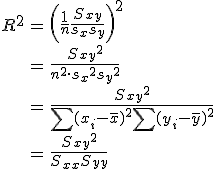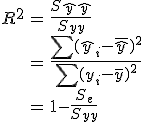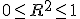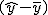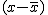回帰 (regression)データをもとに、ある変数(従属変数または目的変数)を 別の変数(独立変数または説明変数)で 予測する式を作るための統計的手法を、 「回帰分析」(regression analysis)といいます。 とくに、独立変数が1つだけの場合を単回帰分析といいます。 複数の独立変数で1つの従属変数を予測する場合は重回帰分析といいます。 回帰直線 (regression line)回帰直線
最小二乗法(least squares method)
回帰式の計算
標準誤差(standard error)
決定係数(coefficient of determination)
回帰の概念
|
メニュー授業内容ケータイで教員にメール今日の5件最新の10件2024-04-122023-07-142023-07-10 total: 1938 today: 1 yesterday: 0 now: 5 |